虚假新闻并非新鲜现象,早在20世纪初,这一概念便已诞生,但社交媒体的兴起后假新闻泛滥成灾,这一概念再度回归到人们视野当中。今年以来,从新冠肺炎到美国总统大选准备阶段,再到种族问题,海量信息的背后藏匿着形形色色的虚假新闻。国内微信、微博等社交平台陆续推出辟谣功能,国外Twitter多次给特朗普平台贴上虚假标签,屡陷丑闻当中的Facebook也积极与谷歌等科技巨头合作,携手治理网络谣言问题。事实核查可谓是近年以来网络空间治理的一大重点,也是一大难点。
社交媒体是否有责任进行事实核查呢?哪种核查方式才是最行之有效的呢?在技术高度的发展的时代,全自动化事实核查的方式被予以厚望。尽管部分技术领导者对全自动化方式抱有高度信心,但仍有相当一部分相关人员并不对此持积极态度,他们认为现在的全自动化事实核查不足以担此重任。在本文中,将具体阐述全自动化的原理和流程,反对的原因,并对现阶段假新闻识别的方法进行总结。
原文来源| International Conference on Integrated Science ;Mashable;Medium
关于事实核查,社交平台的立场
美国的《通信规范法》(Communications Decency Act)第23条规定,管理公开论坛的社交网站只要出于好的动机移除非法内容,不用为用户发帖的内容负责。近日,鉴于Twitter为特朗普针对弗洛伊德事件的评论贴上标签的做法,特朗普正试图为了一己之利窃取法院和国会几十年来制定法律的权力,他根据自己的利益来决定什么是合法的。同时,这一事件也再度引发了关于全自动化事实核查技术的可行性讨论。
 图片来源:Medium
图片来源:Medium
针对事实核查,Twitter和Facebook两家最大量级的社交媒体平台各自表明了态度。
Twitter秉持着「我们有责任」的立场。几个月以来,杰克·多西 (Jack Dorsey)正努力划清界限,并一直对特朗普的挑衅持观察态度。最近,从多次为朗特普推文贴上标签开始,Twitter加大了对假新闻的查处力度,这在短期内赢得了许多用户的支持,但从长期来看,如何以无偏差的、最新的方式辨别新闻的真假性非常具有挑战性。
Facebook认为让平台作为真假新闻的决定者存在风险。以反推特禁止政治广告为例,政治广告的目的是什么?将政治广告作为一个实体,它不仅是为了推广产品更是为了赢得公众舆论。参议员购买选票显然属于政治性,但在发生漏油事件后,石油公司购买水军扭转舆论是否也属于政治广告?这里具体的结果并不重要,重要的是,如何区分政治广告与非政治广告之间的界限?
Facebook与Twitter实际上是两种不同的事实仲裁方式,若处理得当,则都能产生正面效用。
全自动化事实核查背后的质疑
自然语言处理(NLP)是机器学习的子领域,涉及从文本中提取信息并对其进行操作,常用于智能助手、翻译器、搜索引擎和网络商城中。NLP是能够识别真假新闻的候选工具之一。
迄今为止,最好的自然语言处理工具是被称为转换器的神经网络体系结构。
简而言之,转换器先将单词编码为数字空间,再根据翻译、错字修复、分类等不同的目的需求解码为相应的结果。其中的一个关键工具为「Attention」,它能够学习重点关注哪些词汇以及持续多久,而不是硬编码。转换器结合了所提及的这些工具,再加上其他几大改进,是该模型得以高效运作。
 转换器中的数据处理流程。图片来源:Medium
转换器中的数据处理流程。图片来源:Medium
转换器结构行之有效的关键技术点在于可并行化,即一个模型可同时检测大量文字和推文。在线事实核查意味着每个基于文本的帖子在公开发布前或公开发布后不久都能通过该模型进行检测,这里所涉及的运转规模是前所未有的。
举例来说,Twitter每秒钟约新增6000条推文,Facebook则更甚。内容处理的过程是线性的,这也就意味着对GPU的大量需求。谷歌和Facebook在训练模型上投入了数百万美元的资金,而处理数据的过程可能还会大大增加运作成本。尽管负担较大,但事实核查将对公众留下积极的印象,另外平台也可以通过分类器、人工智能帮助筛选出需要核查的部分,减轻压力。
有了合适的模型和服务器,最关键的问题在于,什么为真?基于学习的事实核查方法存在着这样几个问题:不固定的目标,有偏见的数据以及不明确的定义。也正因为此,全自动化事实核查的适用性得到了很多人的质疑。
 图片来源:Mashable
图片来源:Mashable
什么是事实?什么是真相?并非所有人对同一信息真假性的观点都是相同的。尽管存在许多既定的真理,如地球是圆的,但仍然有许多界限模糊、难以区别的信息。在网络事实核查中,用户希望本地发生事件的真实性也能得到识别,但如何从众说纷纭中找出正确的信息呢?
谁是数据库的管理者?并不是所有待检验的真理都能用科学理论进行阐释。对于网络信息,数据标记是必要的,但数据驱动的方法始终存在着偏见与变故。进一步细分,似乎没有合适的管理者候选。例如,如果由科学家决定事实,那么恐怕白人男性信息所占的比例过高;如果由社交媒体决定事实,那么有可能俄罗斯虚假信息将决定事实数据库的基础;如果由纸媒决定,则将可能重塑少数作家的世界观。倘若由以上三者联合管理,听起来是个不错的方案,但总会存在极端情况,信息缺失或者困惑性的偏见。
到目前为止,最佳的解决方案可能是资金支持下的开源事实核查,也就是说,成立独立组织进行定期维护与更新。这是一项耗资巨大的工程,但为了维持开放的互联网社会的稳定却也是必要的。当然,成立开源事实核查组织并不是最终解决方案,之后还需要针对大量潜在的问题进行讨论与敲定。
全自动化事实核查将固化社会不平等
独立非营利组织Full Fact的自动化事实核查负责人Andrew Dudfield称,由于当中存在的细微差别所产生的复杂性,他认为现阶段还无法真正实现全自动事实核查。自动化能够对传统的事实核查形成补充,但无法取代。他还表示,自动化技术能够综合考虑大量信息,将能协助事实核查人员适应网络信息环境的广度和深度。但对于某些任务(如需要结合上下文语境解释语言上的细微差别)人工仍是最好的核查方式。
 图片来源:BBC
图片来源:BBC
纽约大学社会学家Mona Sloane担心,全自动化事实核查将固化偏见。以虚拟社区Black Twitter为例,在这里即使是口语也常被AI过度标记为存在潜在侵略性。因此需要考虑算法采用的数据的性质。人工智能将对所提供的的信息加以整理,如果信息带有偏见则生成的结果也带有偏见。
普林斯顿大学非洲裔美国研究教授Ruha Benjamin在她的书中写道:如果在全自动系统中无法解决这些细微差别,开发人员可能会制造出工程上的不平等现象,从而显著地强化基于种族、阶级和性别的社会等级制度。换言之,提供并未解决社会偏见问题的产品和服务,最终可能会加深社会不平等。在社交媒体平台致力于纠正现有偏见之前,开发全自动事实核查技术似乎并不是解决信息流行病行之有效的办法。
什么是事实核查最有效的方式?
检测假新闻的方式有五种,分别是语言模式、主题无关模式、机器学习模式、知识基础模式以及混合模式,这五者之间存在相互重叠,但其共同作用又能帮助进行更好地识别。
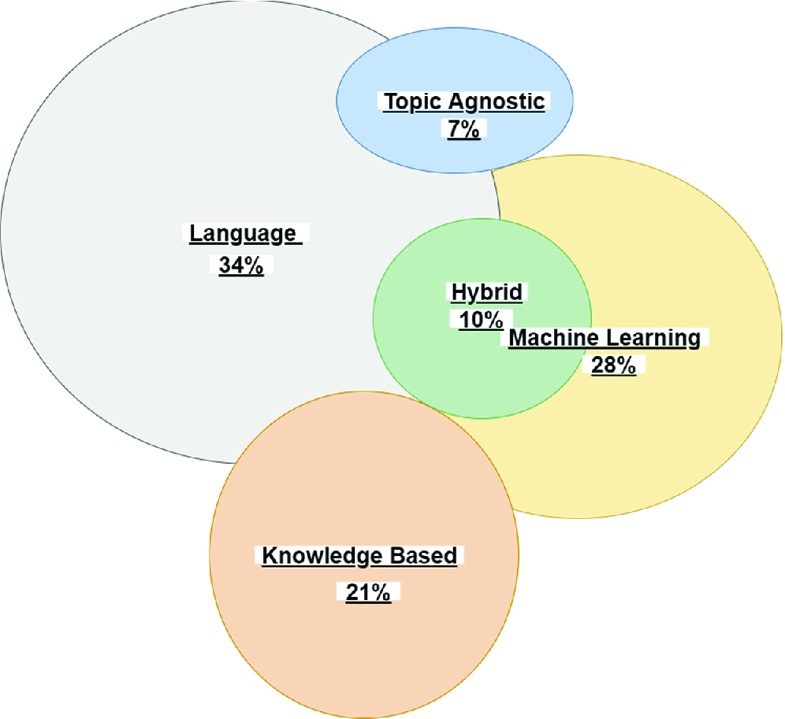 假新闻检测方法类别。图片来源:International Conference on Integrated Science
假新闻检测方法类别。图片来源:International Conference on Integrated Science
1. 语言检测模式
语言检测模式的核心是通过语言学的应用识别假新闻。具体而言,指的是分解句子中的每一个单词,单词中的每一个字母,厘清整篇文章结构以及文章各部分之间的结构关系,也就是说,关注焦点为语法和句法。当前语言检测模式包括以下三种主要方法。
词库:在此种方法下,段落中的每个单词都是相互独立、同等重要的。通过统计单个单词出现的频率进而分析虚假信息的标识,这些标识也被称为n元语法。这样一来,词汇应用模式将清楚地展现出来,通过对词汇应用模式的进一步分析便能识别出误导性信息。当然,由于在将文本转化成数字信息时并没有考虑到上下文信息,词库的方法并不具有充分的实际意义。
语义分析:可以通过个人经历与相似文章中提炼出的主题词相对照,判断新闻的真假性。通常而言,诚实的写者更有可能围绕某个话题做出相似的评论。
深度句法:这种方法是通过「随即上下文无关文法」实现的,具体而言,是采用「分析树」的方式进行深度的句法挖掘。新闻中的每一个句子都将被转换为一组重写规则,这组规则之后被用于分析各种句法结构。通过对比新闻句法与已知假新闻结构,辨别新闻的真假性。
2. 主题无关模式
这种模式将不会分析文章的具体内容,而是通过与主题无关的特征进行检测,具体而言为语言功能和网络标记功能。与主题无关的特征包括:①大量广告②带有醒目短语的长标题③与主流新闻截然不同的文本模式,带有明显的情感煽动性④作者姓名。
3. 机器学习模式
机器学习模式是在大量数据训练的基础上,完善算法,用于假新闻识别。目前已开发出一种被称为「谣言识别框架」的机器学习方法,帮助人们轻松识别假新闻。该框架旨在打击Twitter上的假推文,主要从4个方面入手:推文的元数据,推文的来源,推文的日期和区域,推文的开发时间和地点。通过研究者4个部分,检测信息的准确性,并向人们发出假新闻提醒。
4. 知识基础模式
最近的研究主张将机器学习与知识工程相结合。基于知识的方法能够通过外部来源验证新闻的真假性,具体而言,包括三类:
第一,面向专家的事实核查。该方法要求专业人员通过对特定声明的研究,结合其他类型的研究手动评估新闻的准确性。具体方法是将文本与先前经过事实核查的另一文本进行对比。
第二,以计算为中心的事实核查。此种方法的目的是通过自动的事实核查过程来管理用户,从而识别特定新闻的准确性。其中知识图谱和开放式网络资源也将作为重要的判断源。另有一项名为ClaimBuster的事实核查工具,它结合了自然语言处理和各种数据库查询的机器学习技术,能够实时分析社交媒体推文、采访、演讲等文本的上下文语境,确定事实,并与数据库中已经过验证的事实加以对比后传达给读者。
第三,面向人群集体智慧的事实核查。新闻的准确性判断是一群人智慧的结晶。以众包平台Kiskkit,它提供了一群人共同评估新闻真假性的机会,最终由集体决定其真伪。
5. 混合模式
假新闻通常有三大组成要素:正文、评论、来源。近年来学界提出依靠人力与机器学习相结合的混合模式帮助更准确的假新闻识别。单纯的人力识别仅有4%的可能性准确识别出,且所花费时间几乎翻倍。事实证明,混合模型能够增加识别准确性,并减少识别所耗费时间。其中一种较为有效的模式为CSI(抓取、评估、合成)混合模型。
技术的发展已经使自动化识别假新闻成为现实,但从当前的应用来看,全自动化识别仍为时尚早,对假新闻的识别需要数字工具和人类智慧的共同作用。
结语
虚假新闻诞生于新闻媒体成立初期,兴盛于社交媒体上升之时。不得不说,假新闻的肆虐与社交媒体的兴起有摆不掉的联系,因此,社交媒体平台有义务对该现象负责。从Facebook和Twitter的立场来看,尽管两者存在差别,但都是站在如何更好地治理假新闻的角度,寻求最优解决方案。
事实核查并非简单的语言学和语用学应用,而是需要结合上下文语境甚至社会宏观背景,综合分析加以判断。另外,自动化背后的算法需要在海量信息的基础上自我学习,而信息中隐藏的偏见将导致算法的偏见,从而导致新闻识别结果的偏误。从这个意义上看,事实核查是一个复杂的过程,当前的全自动化事实核查技术并不足以满足理想的效果,人力与机器的混合是最优方案。
另外,有研究表明,人们对假新闻的信任并非出于政治意识形态立场,而纯粹是个人的分析思考与否。因此,提高个人的假新闻判别能力首要方式是通过宣传教育提高个人素质修养。当然,假新闻无孔不入,即使是个人素质极高的人也会存在因缺乏专业知识导致的思维闭环,而识别有误。总结来看,假新闻的认知与治理都非一劳永逸,既需要法制、技术等硬治理层面的持续跟进,也需要包含多种教育手段在内的软治理层面的齐头并进。